JSON
JSON pipeline enables a user to transfer data from JSON file attachments into a user determined data warehouse.
Data Pipelines Details
- Data Pipeline
-
Select JSON from the dropdown
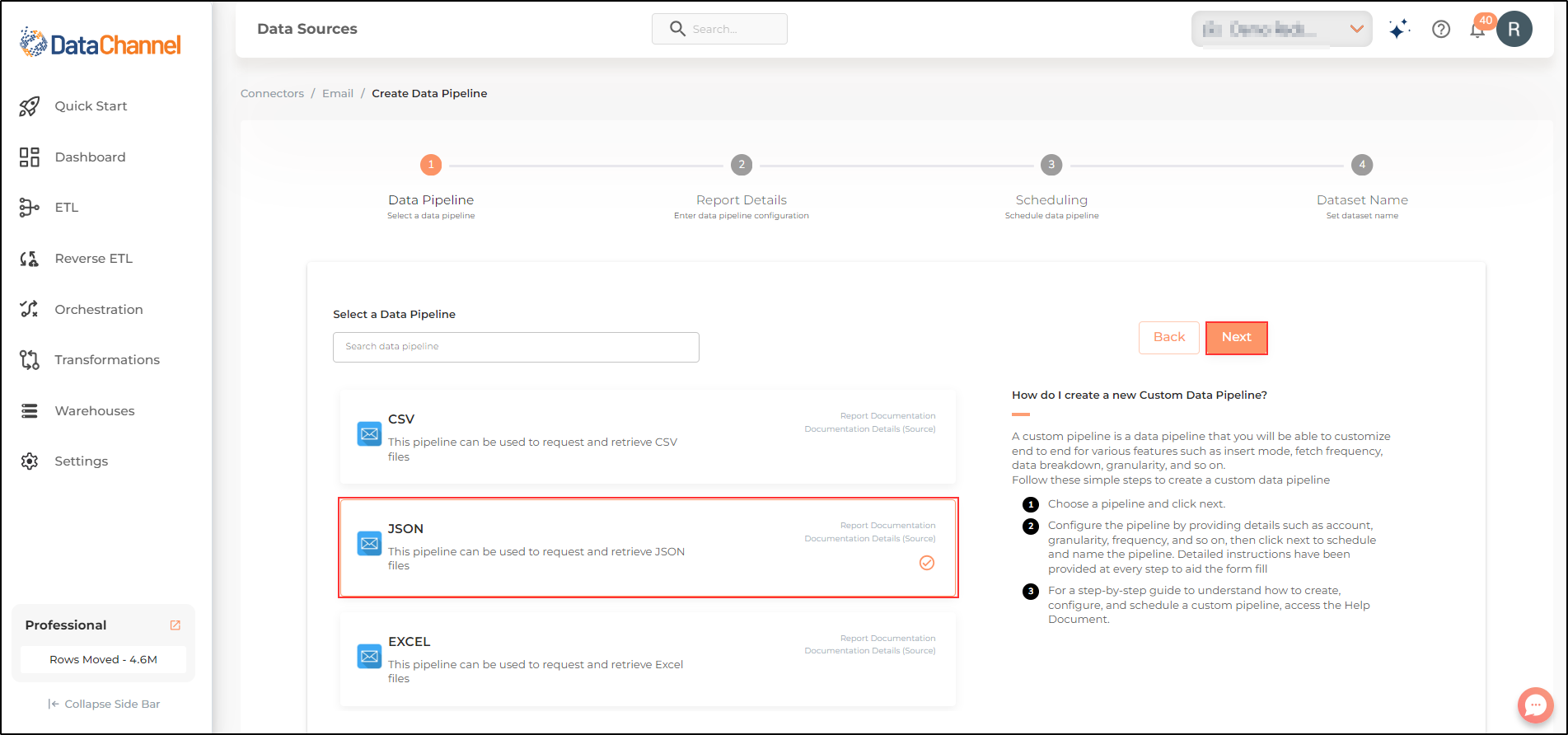
- File Name
-
Enter a JSON file name.
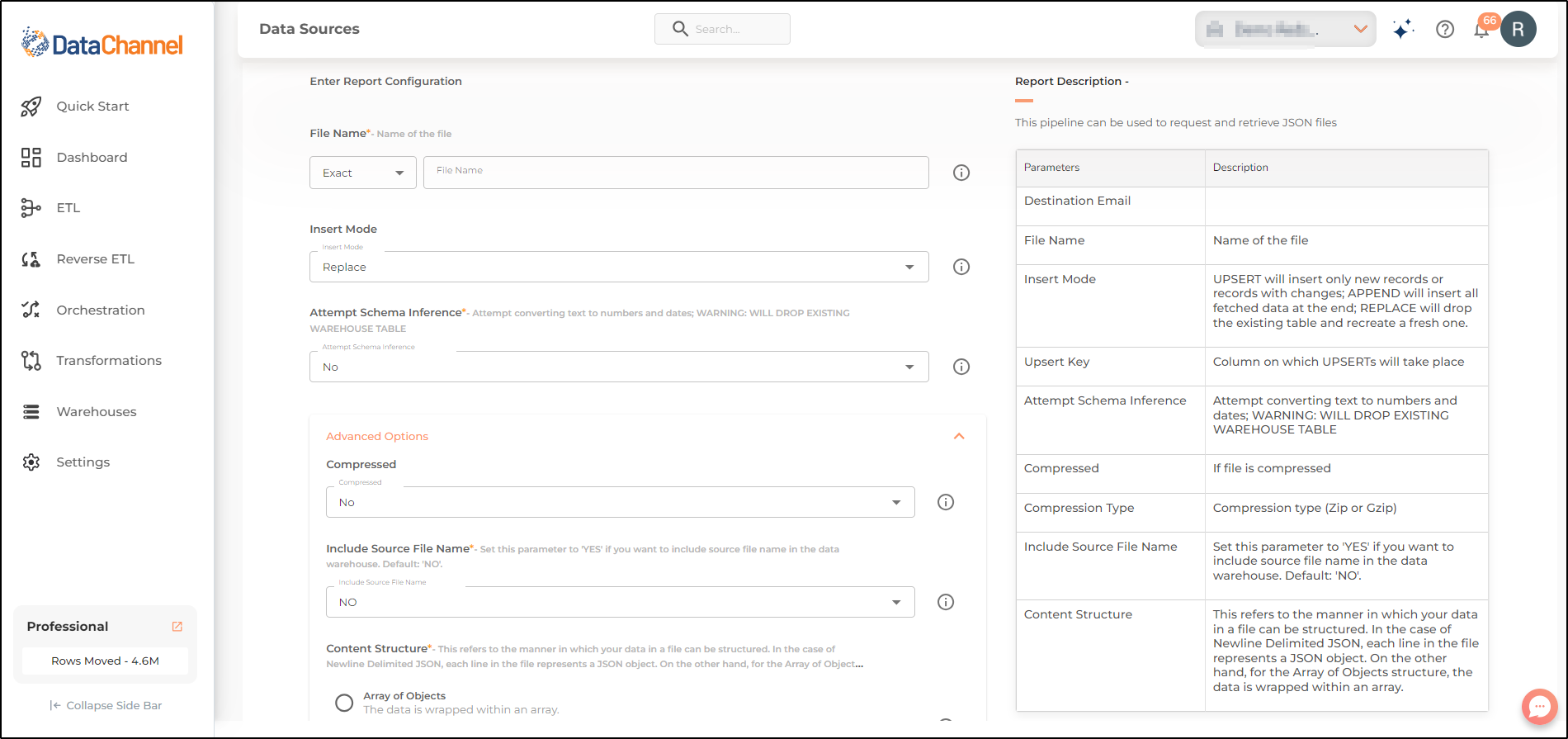
Setting Parameters
Select the fields that are necessary as per the file or folder .
| Parameter | Description | Values |
|---|---|---|
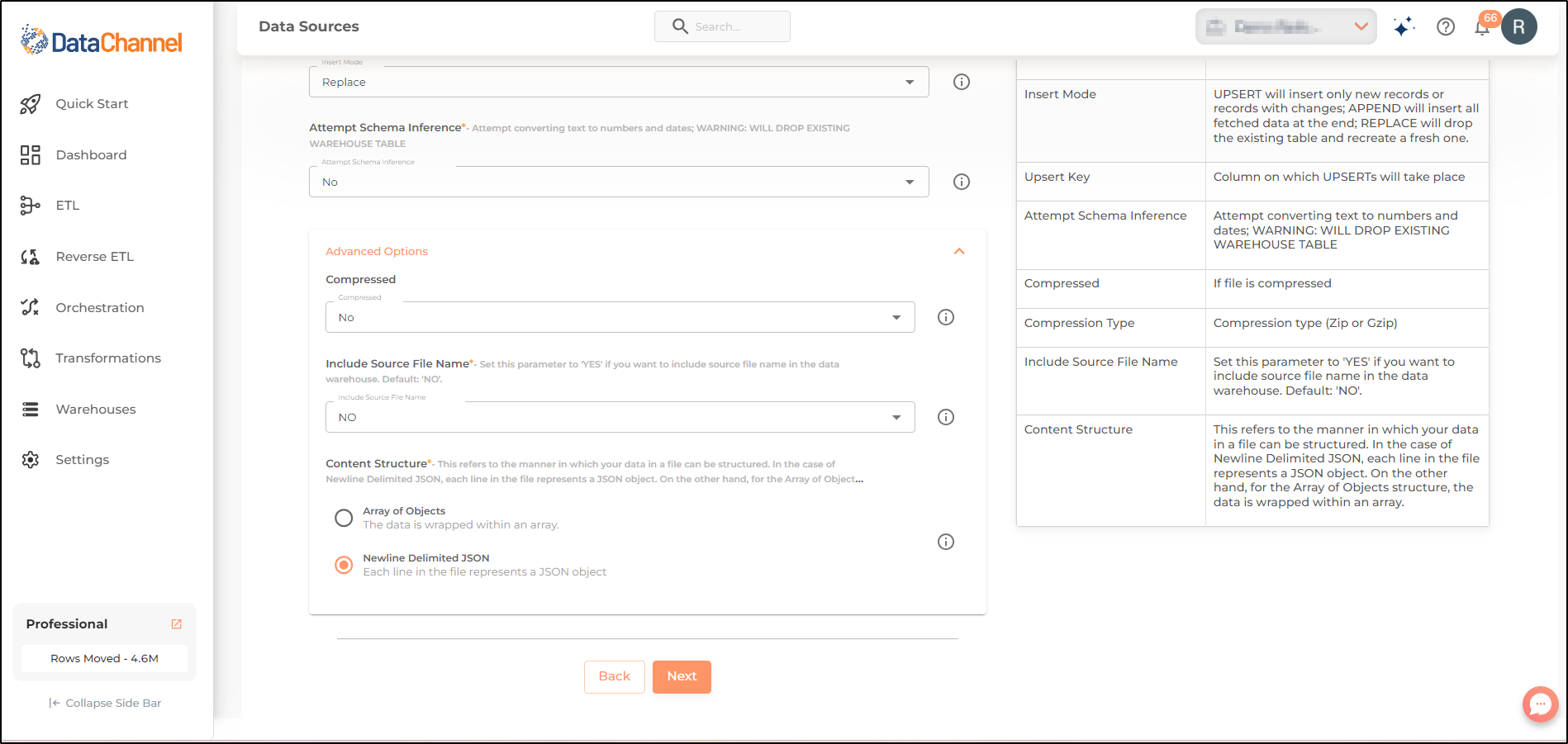
Insert Mode |
Required Specifies the manner in which data will get updated in the data warehouse : UPSERT will insert only new records or records with changes, APPEND will insert all fetched data at the end, and REPLACE will drop the existing table and recreate a fresh one on each run. Recommended to use "Upsert" option unless there is a specific requirement. |
Default Value: Replace |
Upsert Key Dependant |
Required (If Upsert is chosen as the Insert Mode Type) Enter the column name based on which data is to be upserted. |
String value |
Attempt Schema Inference |
Required If Yes then value types will be fetched as it is, eg: Float will be fetched as float. If No then everything will be fetched as string irrespective of its type. |
Default Value: No |
Compressed |
Required Choose Yes or No depending on the file compression |
Default Value: No |
Compression Type Dependant |
Required (If Compressed = Yes) Specify the file compression type |
|
Include Source File Name |
Required Set this parameter to 'YES' if you want to include source file name in the data warehouse. Default: 'NO'. |
Default Value: No |
Content structure |
Required This refers to the manner in which your data in a file can be structured. In the case of Newline Delimited JSON, each line in the file represents a JSON object. On the other hand, for the Array of Objects structure, the data is wrapped within an array. |
Default Value: Newline Delimited JSON |
Still have Questions?
We’ll be happy to help you with any questions you might have! Send us an email at info@datachannel.co.
Subscribe to our Newsletter for latest updates at DataChannel.