CSV
CSV report enables a user to transfer data from CSV files into a user determined data warehouse. For more details on reading and writing CSV files click here
Data Pipelines Details
- Data Pipeline
-
Select CSV from the dropdown
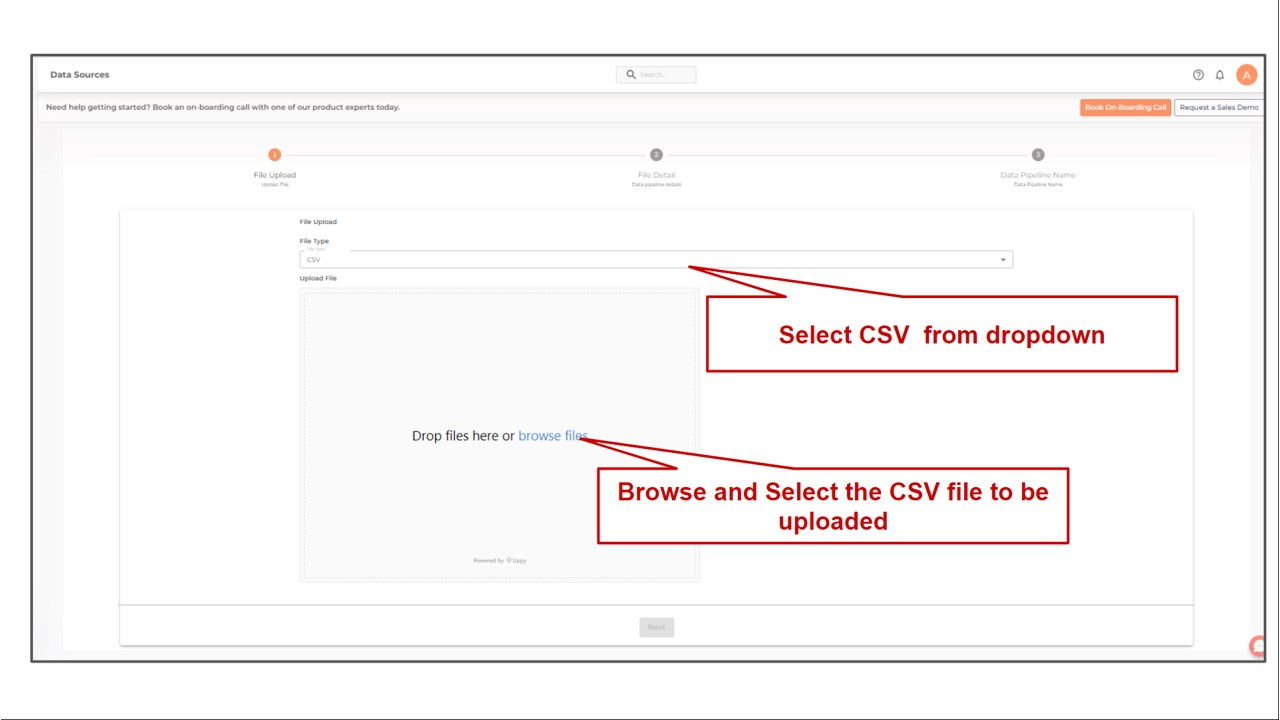
- Choose File
-
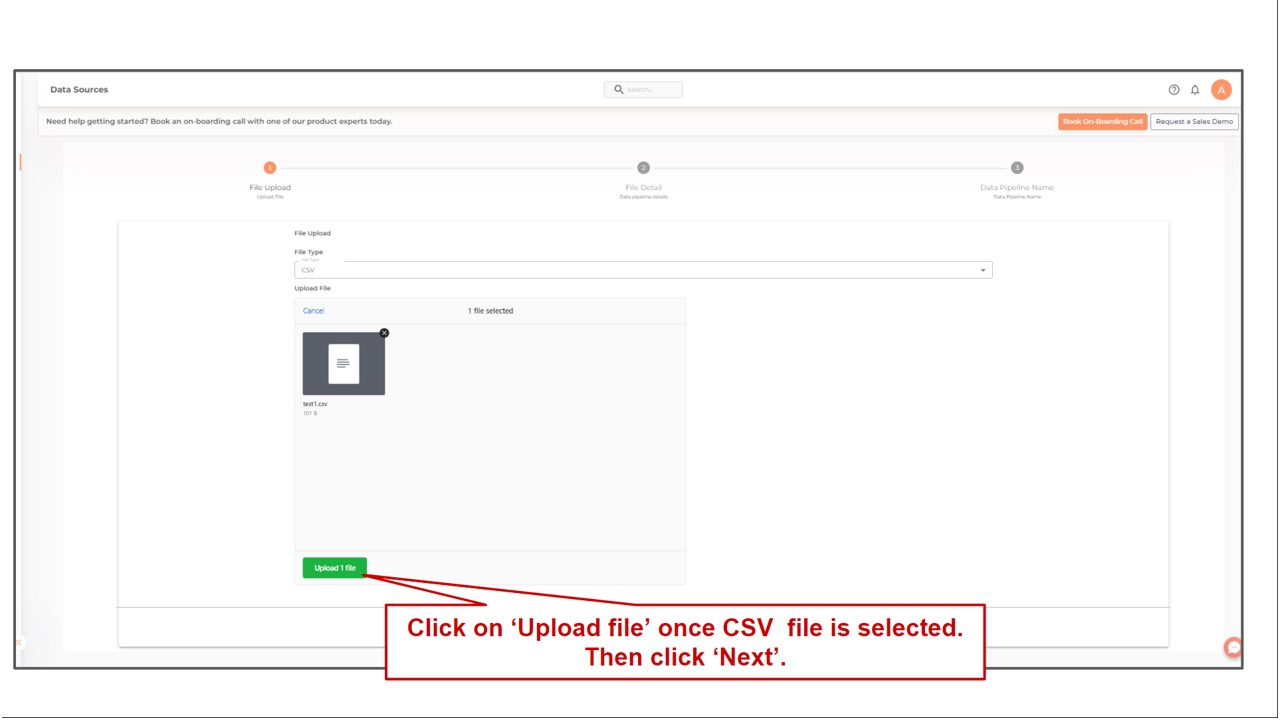
Select a CSV file by clicking on the Choose File button. The CSV file to be uploaded should have a header row that includes the titles of each column.
Setting Parameters
Select the fields that are necessary as per the file or folder .
| Parameter | Description | Values |
|---|---|---|
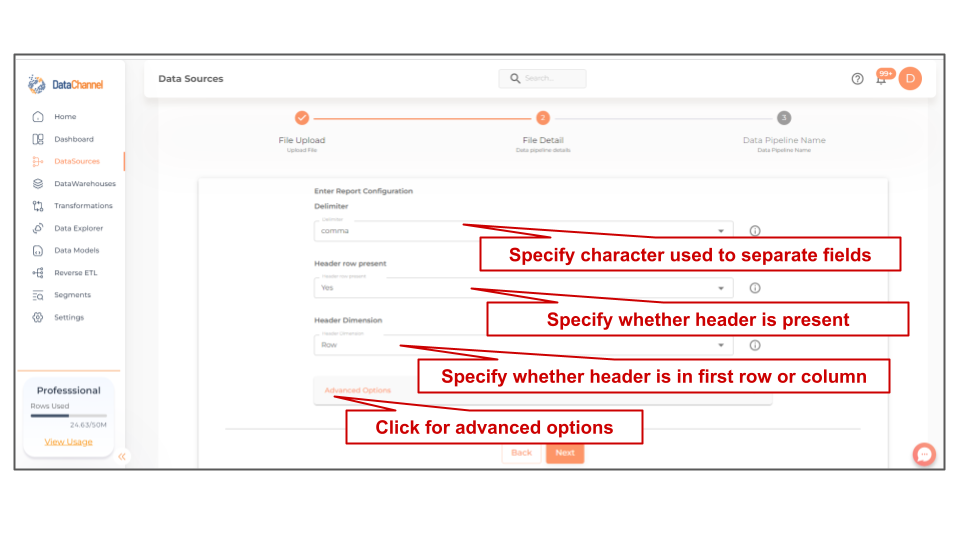
Delimiter |
Required Specify the one character string used to separate fields in the file. |
{comma,pipe,dash,semicolon,space,tab_char} Default Value: comma |
Header Present? |
Required Specify whether Header is present in the sheet. If "No", is selected, the entire range will be treated as data and "column_0","column_1","column_1",…"column_n", will be used as column names in the warehouse. |
{Yes, No} Default Value: Yes |
Header Dimension |
Required Specify whether Headers are present in first row or first column. |
{Row, Column} Default Value: Row |
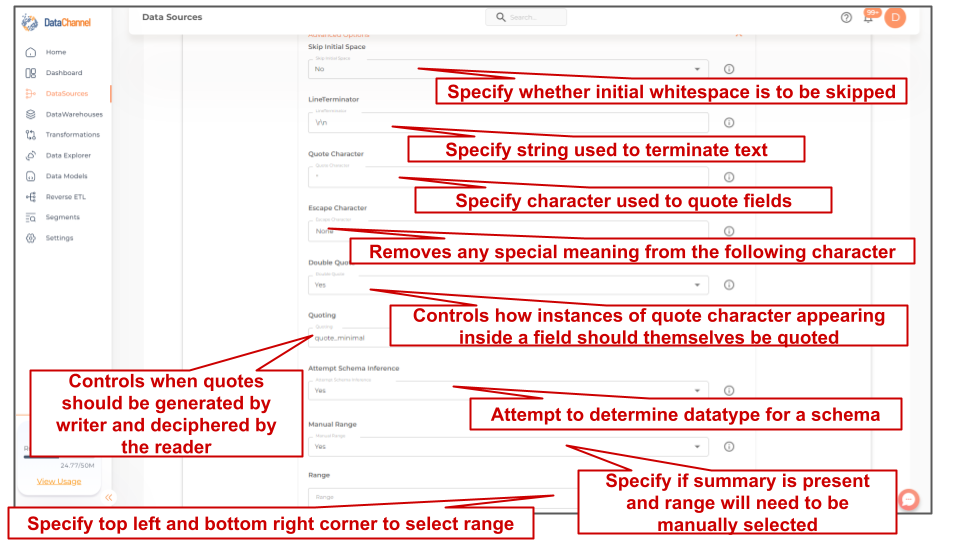
Skip Initial Space |
Optional Select Yes, if the whitespace immediately following the delimiter is to be ignored, else No. |
{Yes,No} Default Value: No |
Line Terminator |
Optional Specify the string used to terminate text |
String value (eg:\r\n) Default Value: \r\n |
Quote Character |
Optional Specify the one character string used to quote fields containing special characters, such as the delimiter or quotechar, or which contain new-line characters. |
String value (eg:") Default Value: " |
Escape Character |
Optional A one-character string used by the writer to indicate that the character immediately following it should be interpreted differently than it normally would. On reading, the escapechar removes any special meaning from the following character. It defaults to 'None', which disables escaping. |
String value (eg:None) Default Value: None |
Double Quote |
Optional Controls how instances of Quote character appearing inside a field should themselves be quoted. When Yes, the character is doubled. When No, the Escape character is used as a prefix to the Quote character. |
{Yes,No} Default Value: Yes |
Quoting |
Optional Specify the type of Quoting : 'QUOTE_ALL' instructs writer objects to quote all fields, 'QUOTE_MINIMAL' instructs writer objects to only quote those fields which contain special characters such as delimiter, quote character or any of the characters in line terminator, 'QUOTE_NONNUMERIC' instructs writer objects to quote all non-numeric fields and reader to convert all non-quoted fields to type float, 'QUOTE_NONE' Instructs writer objects to never quote fields. |
{quote_minimal,quote_none,quote_all,quote_nonnumeric} Default Value: quote_minimal |
Attempt Schema Inference |
Optional If 'Yes', then value types will be fetched as it is, eg: Float will be fetched as float. If 'No', then everything will be fetched as string irrespective of its data type. |
{Yes,No} Default Value: No |
Manual Range |
Optional Specify whether Summary is present in file or not. If 'Yes' then you will need to manually give range of Cells where data is present. It defaults to 'No'. |
{Yes, No} Default Value: No |
Range Dependant |
Required, If 'Yes' is chosen in the Manual Range field If the 'Yes' is selected in Manual Range, you will be prompted to select the Range. Enter the top left cell, followed by the colon operator and bottom right cell to define range. Example is 'A1:B3', A1 is the most top left cell and B3 is the most bottom right cell. It should include headers. |
String value |
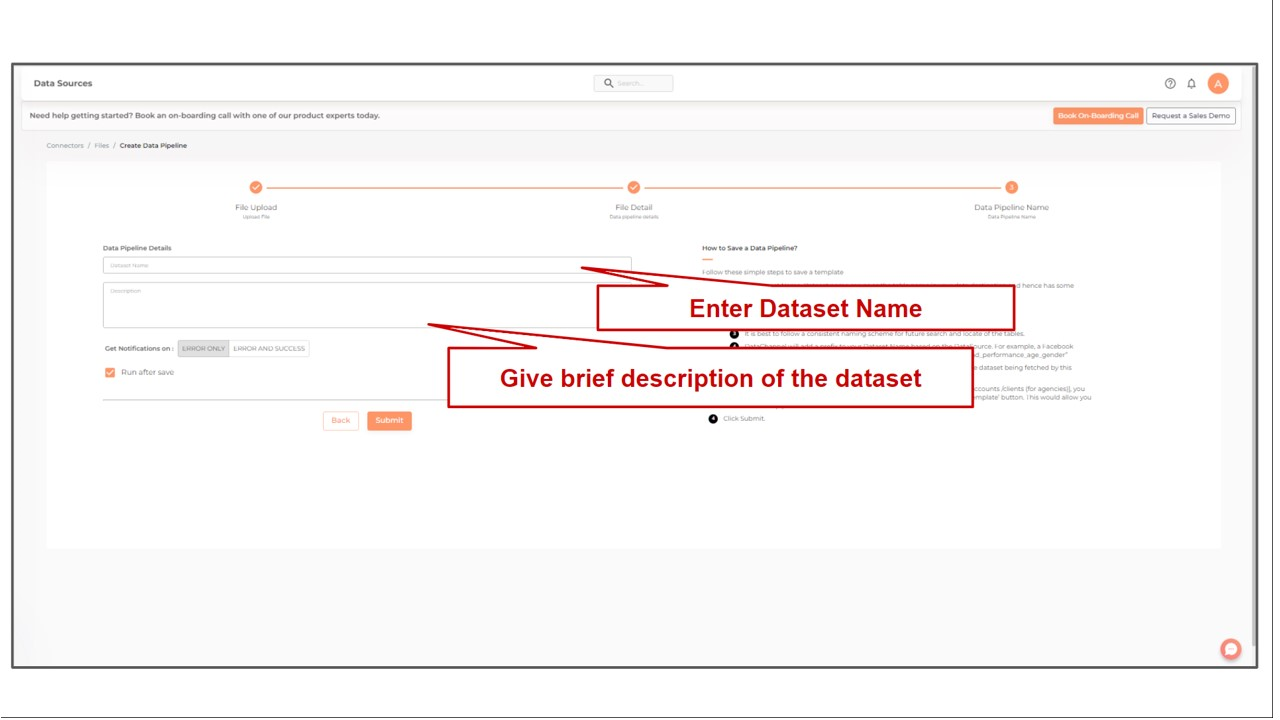
DataSet Name |
Required Enter the DataSet Name |
String value |
DataSet Description |
Optional Enter a brief description about the DataSet here |
String value |
Still have Questions?
We’ll be happy to help you with any questions you might have! Send us an email at info@datachannel.co.
Subscribe to our Newsletter for latest updates at DataChannel.