Data Orchestration
Overview
The modern data stack utilizes various tools to ingest data, clean and transform it, reverse ETL it to the desired applications and run analytics to operationalise the data. Data engineers have a mammoth task ahead of them trying to schedule these operations in a manner that data stays sufficiently fresh & available for downstream use. The volume & type of data generated in today’s fast paced world further add immense complexity to this task. Data Orchestration gives the data engineers an easy way to automate this process, by setting up user-defined workflows that can cascade these activities to run one after another.
Data orchestration is, thus, a multi-step process to manage the flow of your data and activate your siloed and fragmented data. You can create an orchestration by linking multiple Nodes together in their order of execution. You can also add conditions using the Decision Node to define how the Orchestration run is triggered according to your requirements. Furthermore, you can schedule an Orchestration to run at a pre-defined frequency or use the Manual Run option to run it as needed.
Prerequisites
-
Set up your warehouse. DataChannel currently supports the following Data Warehouses:
-
Create the Data Pipelines (for forward ETL) and your Syncs for (Reverse ETL).
-
Create the required Data Models / Transformations that you would like to use on your data as part of the orchestration.
Key Concepts
Decision Nodes- are action nodes that contain a decision to be made, based on the inputs. The answer is either a Yes or a No, and it determines the downstream actions in the workflow.
For example, the Decision node may check "Has the orders pipeline returned 10 new orders?". Based on whether the answer is a Yes or No, it would determine whether to initiate the downstream reverse ETL to Slack. Thus, for every 10 new orders received, you would receive a Slack message in the desired format.
Pipeline freshness- This concept primarily refers to the recency or freshness of data obtained by the previous pipeline run/execution. Depending on the type of downstream operations, freshness of data may be critical. A check to confirm freshness of data is therefore enforced by this feature.
For example, the downstream operations require the data to be not more than 2 hours old between Step A (data extraction) & Step B (data transformation). The pipeline freshness feature can enforce this condition : that unless Step A has executed successfully within the last 2 hours, Step B will not be initiated.
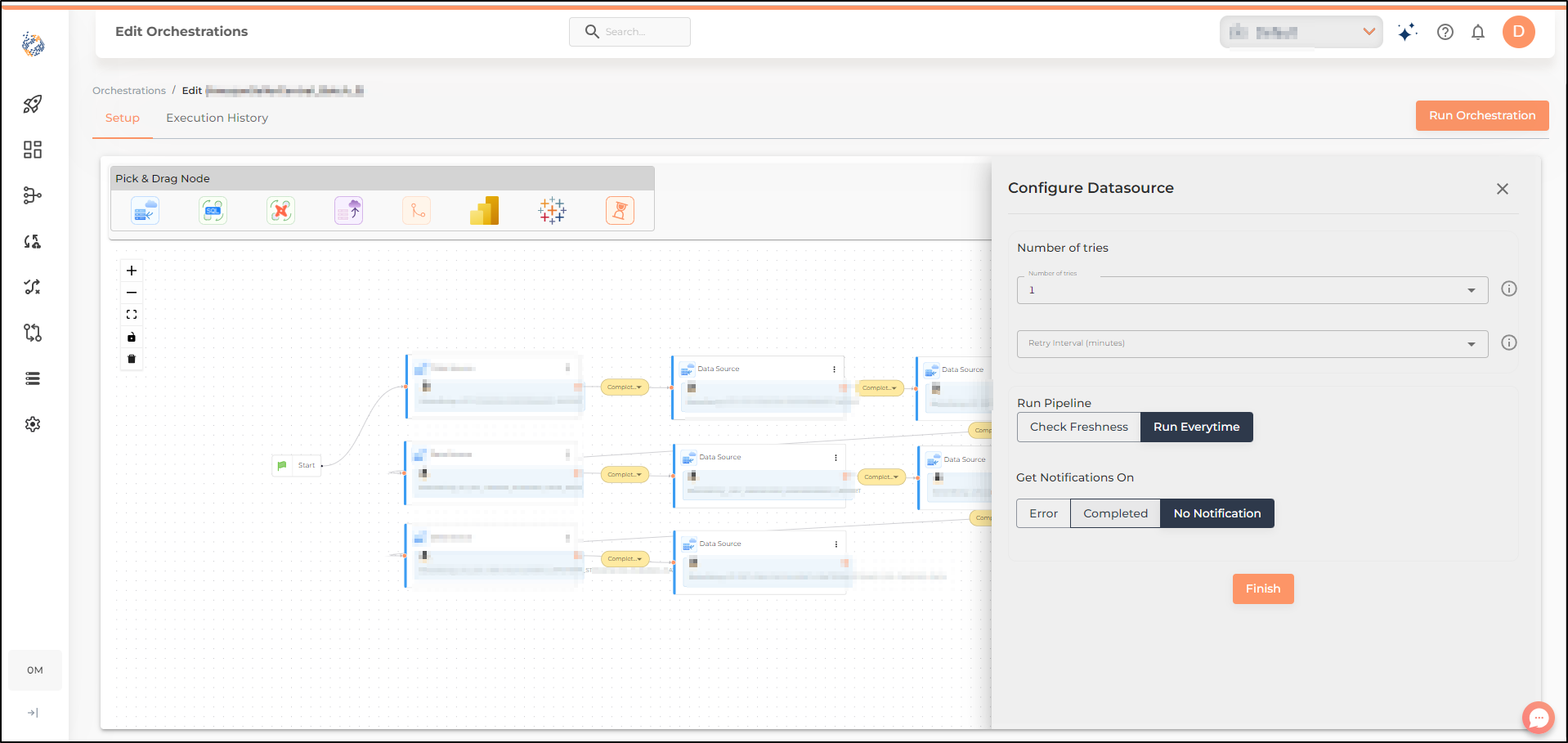
Number of tries- There can be a variety of reasons that may result in a break in the workflow at any particular node. Many of the reasons are beyond anyone’s control and include reasons such as schema changes, permission changes, network issues, resource constraints, data quality issues, preceding node’s run incomplete and the list goes on. To maintain continuity in face of network issues/ resource constraints/ preceding node’s run incomplete, we allow users to define ‘Number of tries’ based on their business requirement. The default number of tries set for any node in the orchestration is 1. Users can however change these settings based on their own requirements.
The maximum number of tries for any node can be 3. This means, in case of failure of a particular step in the workflow, the system will automatically attempt to retry the step 2 more times, before generating an error notification to call your attention to resolve the error.
Retry Interval- Retry interval represents the time period(in minutes) after which a fresh trial to run the node should be attempted.
Scheduling Interdependent tasks- Time is a crucial factor for running orchestrations successfully and probably the trickiest part. When scheduling interdependent tasks, it is important to be mindful of the realistic time frames for completion of preceding tasks. A well planned orchestration will be able to strike the right balance between data freshness and successful execution, ensuring minimal time spent on error handling.
There is no one-size-fits-all approach to scheduling tasks and this must be determined by the business requirements. Orchestration failure and downtime at any node is likely to hamper productivity and resource utilization, hence the importance of proper planning of scheduling the individual tasks.
- NOTE
-
Impact of Orchestration Schedule on Pipelines otherwise scheduled outside Orchestration
When a pipeline/reverse sync/transformation is scheduled outside of the orchestration module as well as within it, both runs will be carried out as scheduled.
However, there may be a case where a scheduling clash occurs when a pipeline/reverse sync/transformation run is slated at the same time as its run as part of the orchestration. In such a case, the previous run will be truncated and the fresh run will start. . Example: If your normal pipeline run is scheduled at 1300 h on Friday and the pipeline run as part of Orchestration is also scheduled at 13:15 h on Friday (while the previous pipeline is still running), the earlier (13:00h) run will be truncated and the pipeline run will start afresh at 13:15 h.
Thus, it is recommended to explicitly schedule the pipelines keeping the above in mind. You may also consider switching the normal pipelines to manual run / pause them once they are already included in an Orchestration run .
Nodes
Get an overview about the different kinds of nodes for creating an orchestration here.
Orchestration level notifications
You can choose whether and how to recieve notifications of your Orchestration Runs (Error and Success). The notifications tab can be accessed from the Settings page from the DataChannel Console.
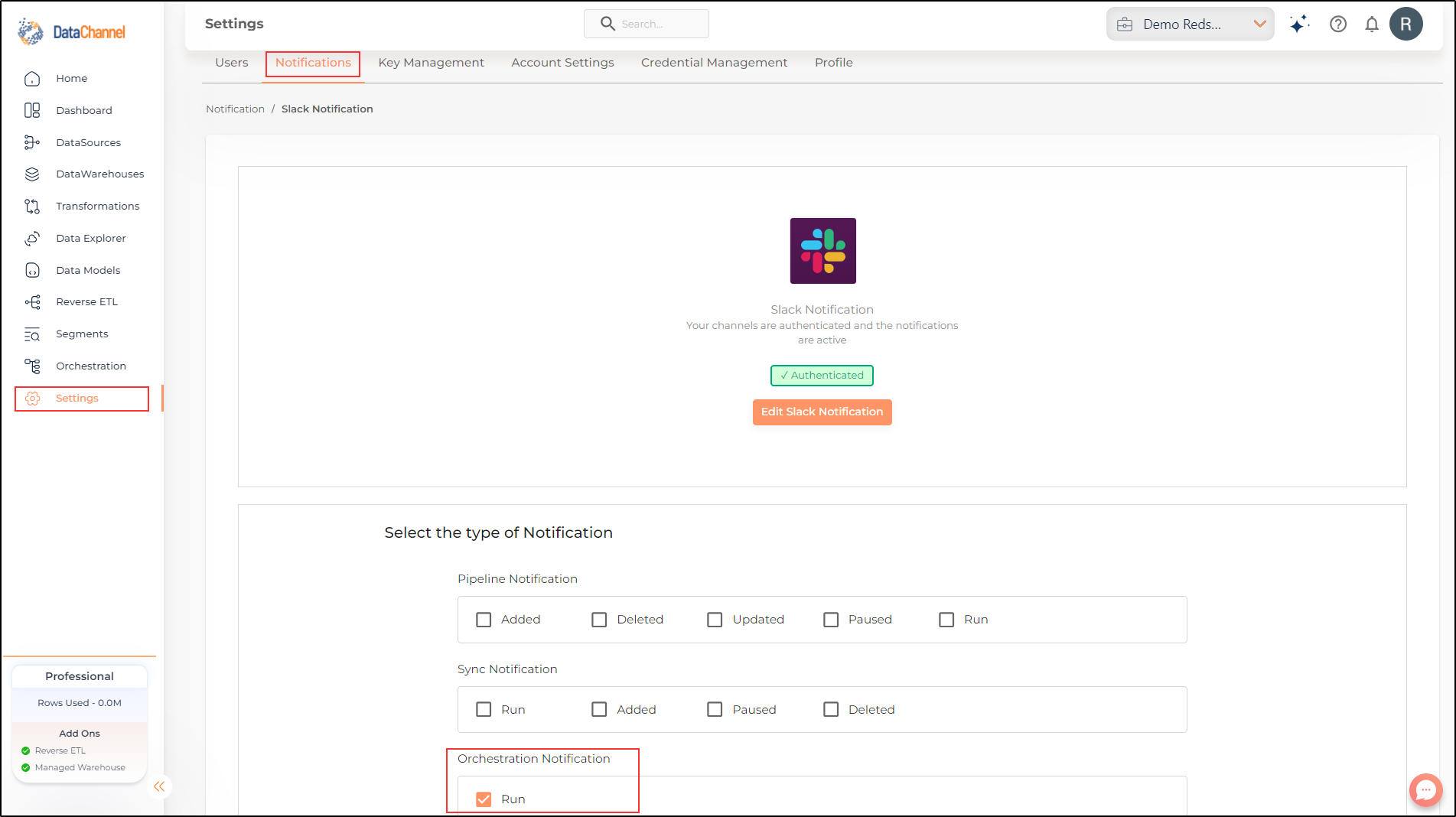
Enabling Node level notifications
Node level notifications have been included for Data Orchestrations. This enables users to choose to be notified on Erroneous/ successful run of a each node of a Data Orchestration. To receive node-level notifications, you will need to mark the relevant checkbox in the Settings tab.
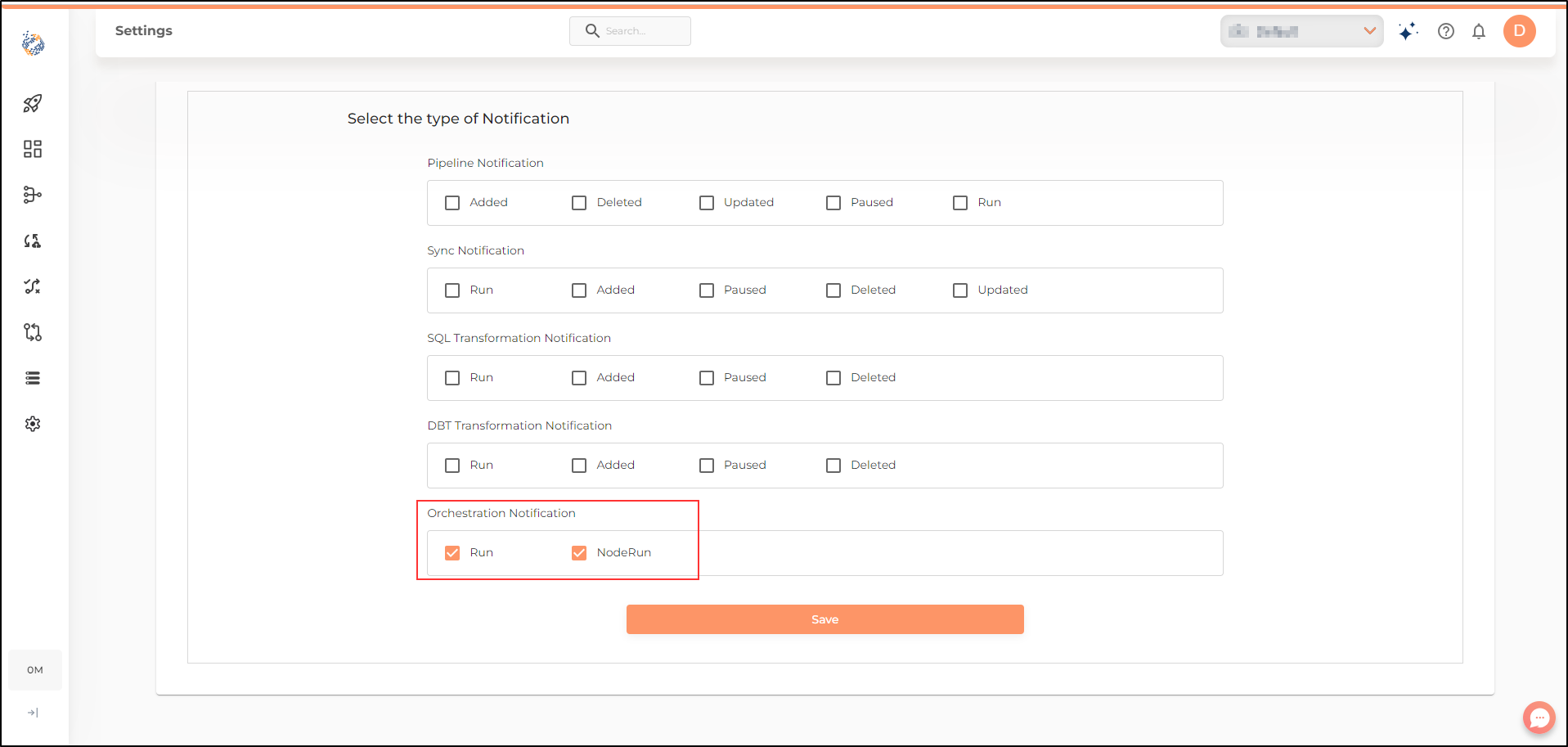
You can select the occurrences for which you would like to receive notifications at the time of configuring the node in the Data orchestration.
Orchestrations - Node status
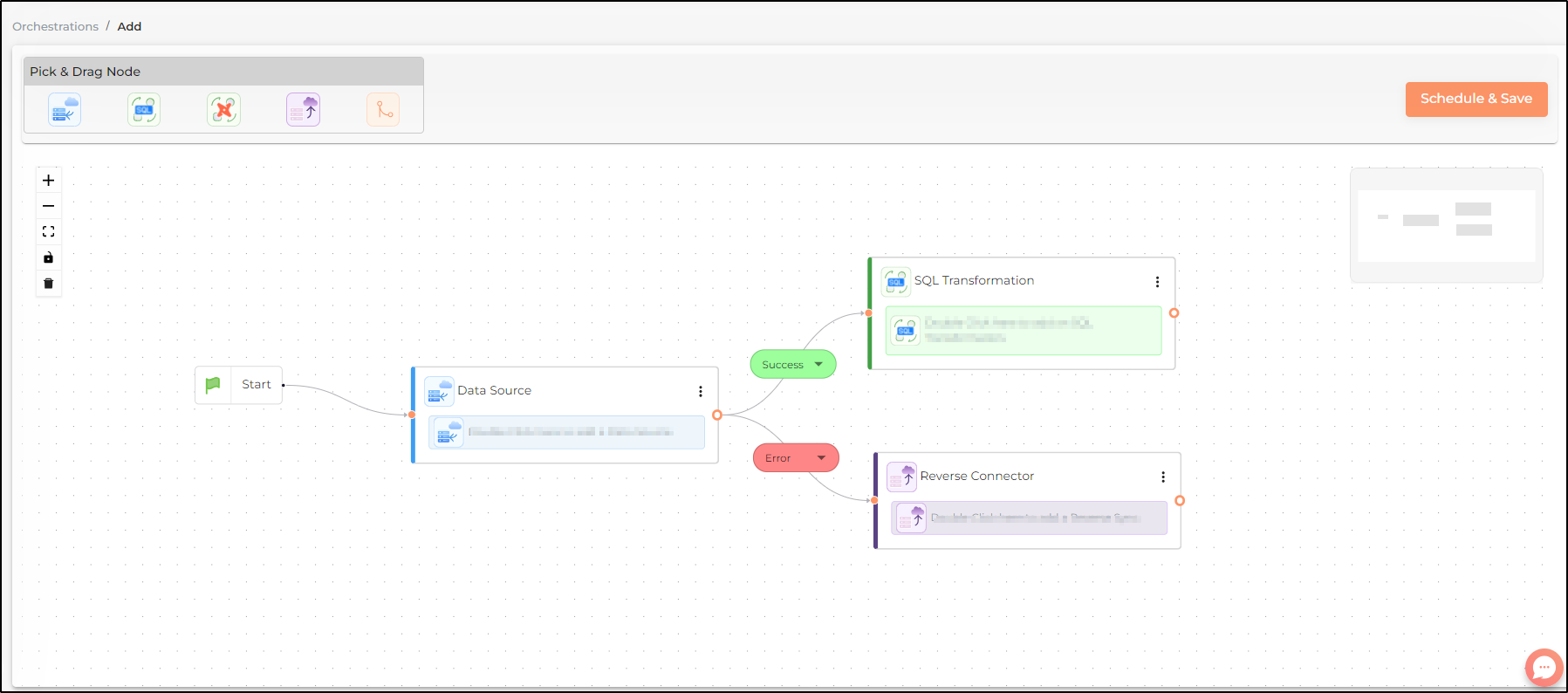
When creating orchestrations, each node has a single output. Users can select the status of the output as success, error or completed(irrespective of success or error) to define the instance in which the succeeding orchestration node should run.
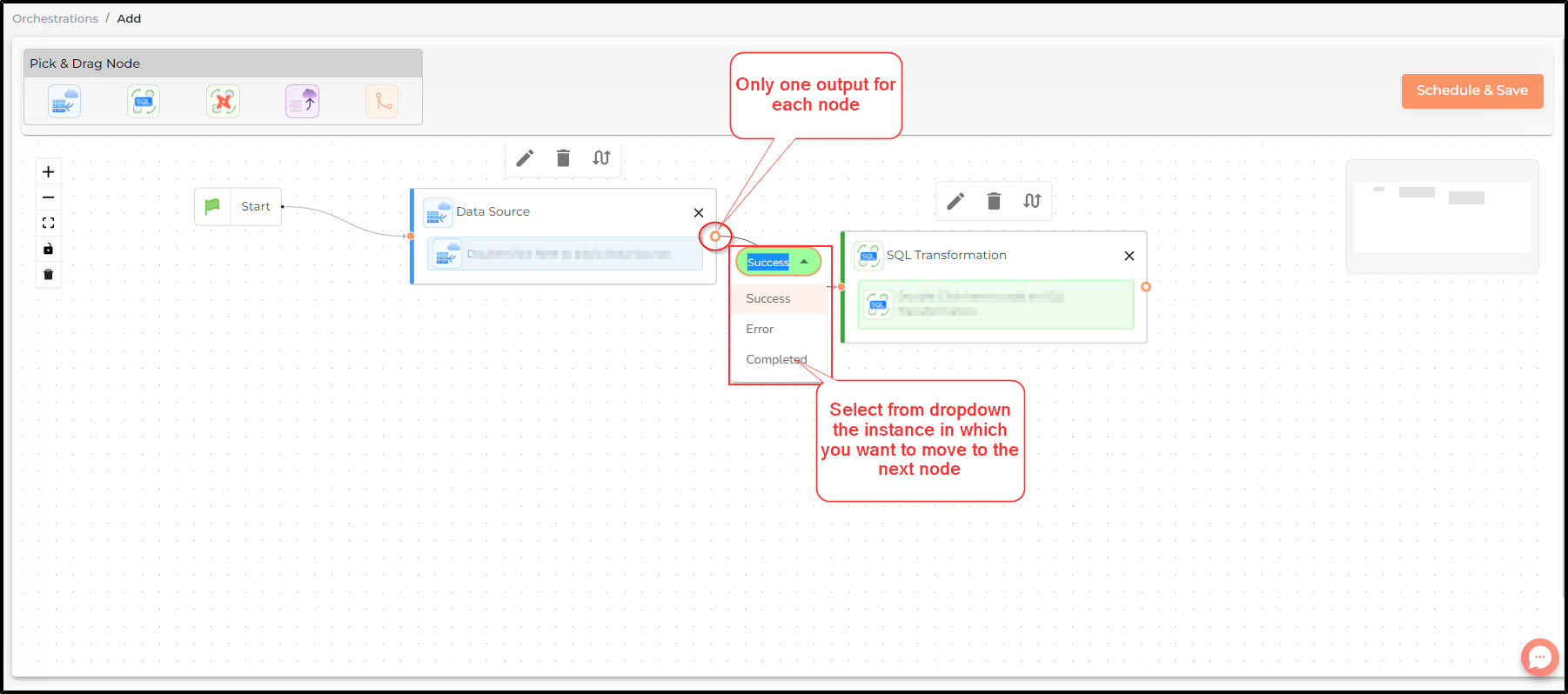
Also note that one output can be connected to multiple succeeding nodes. So, in the example below the user can define separate succeeding actions in case of a successful and erroneous run.
Creating an Orchestration
The step-by-step process outlined here will guide you through the process of creating a new orchestration.
Editing an Orchestration
You may edit and make changes to an existing orchestration, by following the steps listed here.
Manual Run
You also have the option to trigger a manual run of the orchestration at any time.
Deleting an Orchestration
If you would like to delete an existing orchestration, follow the steps outlined here.
Still have Questions?
We’ll be happy to help you with any questions you might have! Send us an email at info@datachannel.co.
Subscribe to our Newsletter for latest updates at DataChannel.